Splunk and CMDB/CMS/IT4IT blog series part 2: Do we still need it/them?
In the first blog in this series, I talked about my background in where content and context were needed. I also talked about why I think that CMDB/CMS/IT4IT content and context are needed within Splunk Enterprise.
In this post, I want to take the time why I think we still are in need of such a CMDB/CMD/CSDM and why I introduce a new solution and abbreviation.
I often see that this topic mostly is discussed from an IT Service Management perspective. And the most commonly known processes that are using that CMDB/CMS/CSDM are the Incident, Problem, and Change (IPC) processes. Although the CSDM (Common Service Data Model) from ServiceNow is meant to be used across multiple other applications and processes.
Next to the IT Service Management perspective, we can see multiple other perspectives like IT Asset Management, security, root-cause analysis (monitoring), change impact assessment, IT4IT, Splunk, etc. Each of those perspectives is using objects out of the CMDB/CMS/CSDM but sometimes needs extra information or relationship types special for that perspective. A relationship “supported_by” is often only important for the IT Service Management perspective but not for the root-cause analysis perspective. One can see a perspective as a view onto the CMDB/CMS/CSDM content and context.
A lot of enterprises have difficulties with keeping up the CMSB/CMS/CSDM quality (3C’s: Completeness, Correctness, and Coverage) as they only treat it from the IT Service Management perspective. That IT Service Management perspective is not the most popular in the application, squads, or DevOps teams, and those new ways of working sometimes seem to be an excuse to do just the minimum work within IT Service Management. But those teams do neglect that they are part of a bigger organization, with a lot of people not understanding what they know, where it is about having the overview, know how all IT Services are related, etc.
I will go through a couple of perspectives in the subsequent paragraphs. But they all need some information (content and context) from a central place:
- ITIL IT Service Management perspective
- Security perspective
- root-cause analysis perspective (monitoring)
- IT4IT reference architecture perspective
- Splunk perspective
And finally I want to mention my new Common Metadata Data Model (CMDM) solution. That solution can be seen as a metadata bridge between all sorts of CMDB/CMS/cloud repositories.
ITIL IT Service Management perspective
CMDB/CMS/CSDM all have their background in IT Service Management. If we want to do follow the ITIL best practices for doing IT Service Management then we all agree that we need some info about CI’s and Services and especially how they are related to support or managed_by groups. An organization has to be able to answer questions as to what service is this particular CI related to, or what Business Unit is using it, and etc.
This is the most known perspective for CMDB/CMS/CSDM content and context. This perspective is focused on the primary process which is Incident management. And for that process, one needs to be able to select a CI (service) for which this Incident is needed. The underlying Service Management tool then also needs the “supported_by” and/or “managed_by” relation to the groups that can act on it.
Most organizations still deliver some standard IT Services on-premise like servers, databases, middleware, etc. These should be part of the CMDB/CMS/CSDM. The best is to see them as services with dependencies of other services. That is also why I came up with the IT4IT reference architecture perspective because in there the services, or digital products as they are called now, are foundational to the lifecycle idea.
Most organizations believe in a central IT Service Management approach and as a minimum, that system should contain the services that that organization is delivering whether that is on-premise, cloud, or even serverless.
I also believe in bringing the Incident, Problem and Changes more easy to the squads, (DevOps) teams. In my CMDM solution that information is stored in there as well together with the user information and support/managed_by groups the belong. As a lot of (DevOps) teams are using Splunk Enterprise in their daily Operations it makes sense to feed that IPC information in user context to them.
Security perspective
You can look at security from different angles but if you see that a certain network IP-address is showing strange behavior then everyone wants to know where it belongs to. And the SOC also wants to know which application(s) it belongs to, who to contact, which business process is involved, and/or which business unit is in breach.
This perspective should contain the shared infrastructure components (IP-addresses, DNS, LDAP, etc) related to the application/services. Security people need to be able to prioritize findings and slice-and-dice the data easily and understand the impact of a security-related finding.
What I often see is that the Security Operations Center (SOC) has their own version of the CMDB/CMS/CSDM and often this is in the form of an excel sheet. The most important reason is that the current CMDB/CMS/CSDM is not containing ALL needed details (spread around in all sorts of tools) and the other reason being that not all security-related tools like SIEM are not CMDB or hierarchy oriented. But the reality is that we now have a shadow CMDB that contains the information that could be necessary for the rest of the organization also.
The Splunk SIEM solution is the most known in this space. At a bare minimum, it needs to have some information about assets like IP-address, MAC-address(es), DNS name(s), owner, priority. And again the place of centrally collecting and maintaining that information is the central CMDB/CMS/CSDM solution. But other information like technology stack, business unit, vendor, development teams is also needed to be able to slice-and-dice the increasing security findings to find out the best way of solving or preventing.
But as a SOC you also need to have an overview of what technologies are used in your organization (on-premise, cloud or …) so you can give guidance, you want to guide about security standards, etc.
Root-cause analysis perspective (monitoring)
Well, this is the most difficult topic for people to understand. Especially if you look to the underlying tools used here because most of them are not CMDB/CMS/CSDM aware and here the issue is maintenance. And the ones I have worked with that were CMDB/CMS/CSDM aware didn’t have the freedom to have objects different outside the CMDB/CMS/CSDM scope/model. So here the issue was rigidness.
That is why I really like Splunk Enterprise. Splunk Enterprise offers a lot of flexibility and freedom but is also not CMDB/CMS/CSDM aware. That’s why I’ve built a solution that brings CMDB/CMS/CSDM content and context to Splunk users. A couple of new search commands and voila we can use Splunk data in context or use context to search Splunk data. It is this flexibility of Splunk that makes it possible to extend the platform.
More and more business processes are digital and often spanning multiple different systems. These processes should be monitored. So if one of the steps of the process is starting to take a longer time to process, someone in the organization wants to know why that is the case. This is what we know as root-cause analysis. To do this one needs to know the relation between the business process, the steps involved with dependencies of the services, and if needed even with dependencies to infrastructure.
Organizations that work with containers, and/or micro-services do know that monitoring is a challenge due to the flexible amount of running services but also the flexibility of where they are running. This is where the Observability suites come into play. Those Observability suites are designed to cope with that amount of services and amount of dependencies. From a central CMDB/CMS/CSDM perspective the Observability suite can be a good source for micro-services and their dependencies with other (micro)services. In this scenario, the Observability suite can contain the relationship with the underlying infrastructure.
IT4IT reference architecture perspective
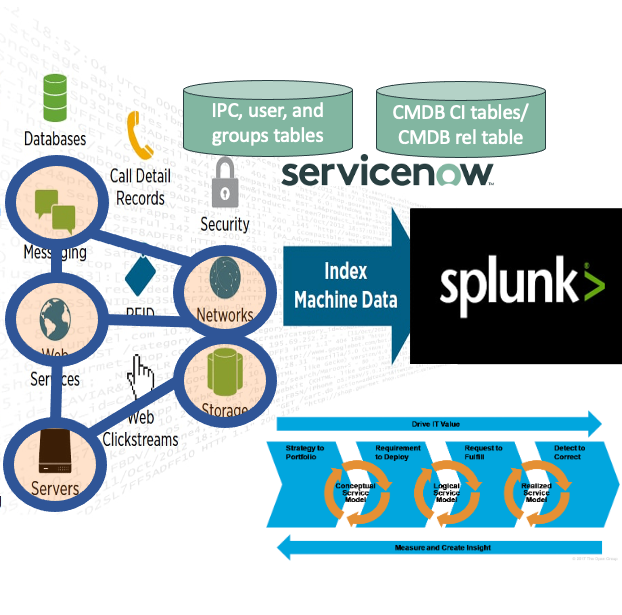
What I really like about the IT4IT reference architecture is the use of the Service/product backbone and all the data objects that are needed to achieve those Services/products. I do see an increasing interest in the IT4IT standard but still, not everyone knows the standard so I thought to share a picture relevant for this blog. If you want to know more about IT4IT the please go to https://www.opengroup.org/IT4IT.

In the above image, the purple circles depict the Service Model backbone going from the left with “Conceptual Service” to the right where we will find the “Actual Service”.
The black circles are showing the data objects needed e.g. Build package, or Change request, or service contract. And probably you will recognize most of those data objects although maybe informally.
DevOps teams are doing both development work and do the operations for the services they deliver. They start doing development work on the “Logical Service”, they have one or more “Service Release” that people can request and they have from one to thousands “Actual Services” in operations. The IT4IT reference architecture will help in specifying the data objects that are needed to have a successful service at the end.
Looking at this from a Splunk perspective and who is using Splunk enterprise the most, then that are the DevOps teams. And from their perspective, they are interested in following what is happening in between the logical service and the actual service, and they want to know the usage and health of their actual services. So those DevOps should be able to have the IT4IT service model backbone information available in Splunk so they can use that for their dashboards en drill-downs. I mean it should be ideal if those teams see their list of services within Splunk with linkage to depending services or locations where to find documentation.
Splunk perspective
Yes, I know that this is not a very well-known perspective. Meeting with several Splunk customers and users of Splunk it became clear that they love working with it. But especially the users of Splunk have issues with the maintenance of the severe knowledge objects they can create. Often these knowledge objects are created by someone (very) well know to Splunk and that person loves the flexibility of Splunk. But if such a person leaves the team or gets a different focus it is difficult for others to understand how these knowledge objects are related to each other. If a change has to be made were to make it.
Often Splunk is used for application security and application/service monitoring (e.g. Splunk ITSI) and then the question becomes which application/service is doing which application security controls or is doing service monitoring. All that information is necessary to understand when using Splunk in a large enterprise organization and to be able to slice-and-dice what is taking place. One of the other use-cases of this Splunk data is to find knowledge objects that are not referenced somewhere.
My new CMDM solution gets all those Splunk knowledge objects, translates and reconciles them, and connects them to existing CMDB/CMS/CSDM information within the CMDM. This also helps in finding out groups of users that are using certain functionality of Splunk or not.
What data should go into the new CMDM solution?
It all depends on the perspective from which the data will be used. Although there is a lot of information that should be in there in general like servers(hosts), databases, Application Services, services, business process steps, etc.
But I want to have the Incident, Problem and Change information in there as well as the relationship between users and support or managed groups. This makes it possible to find the rights groups for a particular user and then find related IPC or CI information.
Personally, I do think that we need to include the metadata of Splunk knowledge objects in the CMDM.
And I can imagine that organizations want to include some IT4IT data objects and DevOps-specific objects in the CMDM.
CMDB/CMS/CSDM within a container or serverless context
Some would say that also all the containers and information of serverless environments should be included in a CMDB/CMS/CSDM/CMDM. I personally think that we need to include at least the services and dependencies with other services and that we need to leave the dependencies with infrastructure up to the Observability tooling. How many services are running and on what infrastructure component is often only interesting to know if there is an issue. Also, the dependency on infrastructure can be different for each individual service call. So better have a decent integration with those Observability tools.
Quality of the CMDB/CMS/CSDM/IT4IT
Often a concern for enterprises is that they know that the quality of their CMDB/CMS/CSDM is not up-to-par. They most often do not talk about the quality of a certain perspective so more the quality as a whole. And by not talking about the perspective it is also difficult to convince people to do something.
The other point why people are complaining about the bad quality of CMDB/CMS/CSDM is that in the past adding or updating CI’s in it was a manual effort and sometimes “forgotten” due to all other activities. And to some degree, it stays a manual effort. Because there are logical CI’s like the name of an application or the business process it delivers services to, that is not easy to collect automatically, although ideally it should be fed from another source.
Luckily we see a great shift. Organizations are doing on-premise discovery of hardware, operating systems, databases, applications, etc.
For organizations moving to the cloud, it becomes even easier as those cloud providers offer good “config” APIs to integrate that part of the CMDB/CMS/CSDM into the centralized one. And a change to configurations in that cloud environment can automatically be tracked and result in an update to the central repository. With the cloud, teams can mark (tag) their own cloud services and those tags can then be re-used for the integration process with the centralized CMDB/CMS/CSDM.
We also see more and more services that are automated. So if an instance of that service, e.g. compute Linux service, is requested it will organize the needed other services like IP-addresses, DNS names, and important updates to the existing CMDB/CMS/CSDM, etc. This automation of standard on-premise services will boost the quality of the on-premise standard IT Services.
I totally believe that a centralized approach is still needed and I also believe that enterprises are able to keep up a good quality of their CMDB/CMS/CSDM by using integrations and discovery. But bring the CMDB/CSM/CSDM content/context usable to the teams and let them also add their type of data into the model.
Is there a life without context?
Ok, let me try to challenge myself in thinking about all the things we can do without knowing the full contextual picture. The only way I see this is going to work is if application teams/DevOps teams/squads are really delivering their thing as a Service. Whether this is on-premise, monolithic, or micro-service. And with that, I mean that they really know exactly the health of their input, if the input is possible at all, the health of their output, and the health of all of their dependencies to other services. And if you deliver things as a service it also implies that you have set up proper service level agreements and service level objectives. It also means that you have the type of monitoring/AIOps/observability that suites your service.
The reallity though is not all teams delivering services as it sometimes seems very difficult to describe the service including the inputs and outputs. And if teams have not defined those services, and unfortunately this is what I mostly see, then there is a big chance that some visibility into the health is missing.
If services are defined correctly and there are contracts for them then I can see that only those services are part of a service catalog including. But as this ideal world is not there there is need for a lot of people in the organization to know those services and how they depend on each other and sometimes how they related to middleware/databases/applications/infrastructure.
You could say that it is up to the teams to think about the technologies they use to develop/create/maintain those services. From an organization’s point of view, this becomes a nightmare. Because what if old or vulnerable technology is used, or developers are moving, or… So from an organization perspective, you want to have more details about each of the services, the technologies in use, the dependencies they have, the teams that are working on it, maybe even versions of implementation details, etc. So to me, we end-up again capturing some service details into a central repository to do that analysis. And the same data can then be used to do Service Portfolio Management, Vendor analysis, Security impact analysis, etc.
So NO, I do not see how we can keep doing without knowing context.
Solution: Common/Corporate Metadata Data Model
The term CMDB is often a red flag for most of us. And I must say the CMBs I have seen so far is surely not ideal. But most of us also agree on the potential value of it when the content and context is of good quality.
Some people know CMS but this term is not that generally accepted. But the Configuration Management System (CMS) was more what it should be.
ServiceNow is having both the term CMDB as CSDM where the latest is an attempt to align with the IT4IT reference architecture and also to align the modelling so that multiple ServiceNow applications can work together.
But none of them is really covering the centralized view of all of the metadata over all of those CMDBs, CMS’ses, cloud configs, etc. That is why I have come up with Common Metadata Data Model (CMDM) or some could see it as a Corporate Metadata Data Model (CMDM). The CMDM can solely be used to do some metadata analysis but can serve as a distribution point as well.
Conclusion
Well, I can be short of that: With all the great IT themes (cloud, micro-services, serverless, API’s, etc) that are happening, enterprise organizations still want to know: how are those IT services depending on each other, what is the impact of to other services, if one of them is failing where does it come from, etc. So even within the context of all the great IT themes, teams creating and operating those are still part of a bigger IT services landscape with tons of other IT Services and as such also other teams and people. Information about service health/state and dependencies with other services is crucial for more roles in the organization.
Subsequent blogs
In the subsequent blogs I want to cover the following:
- The functional explanation of my new CMDM solution initially started for Splunk and ServiceNow, what is there already on the market, and why I think Splunk should be involved. Please see the following post: Let Splunk Enterprise and ServiceNow really work together
- What does this CMDB/CMS/IT4IT data bring to you if the CMDM solution is in place and by using Splunk?
- Can the CMDM solution be used to improve the quality of CMDB/CMS?
- Can Splunk be used as a source for CMDM and if so how?
- What about CMDM and IT4IT?
- Can this CMDM solution help in improving and/or even speeding up the adoption of central CMDB/CMS and/or IT4IT?
If you want me to cover more topics or cannot wait for the other blogs to come please get in contact with me by filling in the following:
You must be logged in to post a comment.